pacman::p_load(sf, tidyverse, MCI, tmap, ggstatsplot)18 Market Area Analysis for Retail and Service Locations using Huff model
18.1 Overview
Market area analysis (also known as Trade Area Analysis) is the process of defining and studying the geographical area from which a business draws its customers. It involves analyzing data on consumer demographics, spending habits, and competitors to understand market viability, identify opportunities, and inform decisions about location, marketing, and expansion. It often combines empirical observation, like customer spotting, with mathematical models to identify market segments and understand customer behavior.
Huff model is a geospatial analysis method commonly used in market area analysis to predict the probability that a consumer from a specific area will patronize a particular store, based on the store’s attractiveness and distance relative to competitors. It calculates a store’s market share by considering factors like size or sales for attractiveness and distance or travel time, with the probability decreasing as distance or competition increases. This tool helps businesses assess potential revenue, define trade areas, and make informed decisions about site selection
18.1.1 Learning Outcome
In this hands-on exercise, you will gain hands-on experience on how to perform market area analysis by using Huff model of MCI packages.
By the end of this hands-on exercise, you will be able:
- to import GIS data into R and save them as simple feature data frame by using appropriate functions of sf package of R;
- to import aspatial data into R and save them as simple feature data frame by using appropriate functions of sf package of R;
- to clean and tidy the data sets so that they are ready for the analysis,
- to compute distance matrix between the origins (i.e. villages) and destinations (i.e stores),
- to computer interaction probability using Huff model, and
- to visualise the market area by using tmap and ggplot2 packages.
18.1.2 Setting the scene
A fast-food franchise is a business model in which an individual (the franchisee) acquires the rights to operate a restaurant under an established brand owned by a franchisor. This arrangement typically involves franchise fees and adherence to standardized operational procedures. Key considerations prior to investment include the scale of initial capital outlay, the strength of the brand, and the strategic importance of store location. Capital investment requirements vary significantly, generally ranging from approximately $200,000 to more than $2 million. Major global fast-food franchise brands include McDonald’s, Burger King, Pizza Hut, KFC, and Taco Bell.
In this exercise, you will assume the role of a data analyst within the business development team of a fast-food franchise. Your objective is to delineate the trade areas of existing stores in Taichung City and to produce corresponding spatial maps to support market analysis and strategic decision-making.
18.1.3 The data
Four data sets will be used in this hands-on exercise, they are:
Geospatial data
- STORES_TN, store locations data in ESRI shapefile format.
- VILLAGE_TN, village boundary data in ESRI shapefile format.
Aspatial data
- pop2019.csv, population data of Taichung City in 2019. H_CNT, P_CNT, M_CNT, and F_CNT indicate Number of household, Total population, Male population and Female population respectively.
- Store_sales_data.csv provides store sales data, and
18.2 Getting Started
Before we getting started, it is important for us to install the necessary R packages and launch them into RStudio environment.
The R packages need for this exercise are as follows:
- sf for handling geospatial data and performing geoprocessing function such as computing distance matrix,
- MCI for performing Huff and MCI modelling,
- tidyverse for performing data science tasks including visualisation,
- ggstatsplot, an R package that extends the ggplot2 visualization package to combine data visualization with statistical analysis, creating plots that include statistical test results directly, and
- tmap for plotting cartographic quality thematic maps.
The code chunk below installs and launches these R packages into RStudio environment.
18.3 Importing Data
18.3.1 Importing geospatial data
First, st_read() of sf package will be used to import the three geospatial data sets into R environment by using the code chunk below.
stores <- st_read(
dsn = "chap18/data/geospatial",
layer = "STORES_TC")Reading layer `STORES_TC' from data source
`C:\tskam\r4gdsa\chap18\data\geospatial' using driver `ESRI Shapefile'
Simple feature collection with 28 features and 3 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: 202702.9 ymin: 2662196 xmax: 232773.2 ymax: 2693557
Projected CRS: TWD97 / TM2 zone 121town <- st_read(
dsn = "chap18/data/geospatial",
layer = "TOWN_TC")Reading layer `TOWN_TC' from data source `C:\tskam\r4gdsa\chap18\data\geospatial' using driver `ESRI Shapefile'
Simple feature collection with 28 features and 7 fields
Geometry type: POLYGON
Dimension: XY
Bounding box: xmin: 194797.1 ymin: 2654887 xmax: 240450.2 ymax: 2703838
Projected CRS: TWD97 / TM2 zone 121village <- st_read(
dsn = "chap18/data/geospatial",
layer = "VILLAGE_TC")Reading layer `VILLAGE_TC' from data source
`C:\tskam\r4gdsa\chap18\data\geospatial' using driver `ESRI Shapefile'
Simple feature collection with 622 features and 10 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 194797.1 ymin: 2654887 xmax: 240450.2 ymax: 2703838
Projected CRS: TWD97 / TM2 zone 121The output print above shown that the three data sets are in TWD97 / TM2 zone 121 (i.e epsg: 3826) projected coordinates systems.
Important
For any geospatial analysis, it is important to check and confirm that all the geospatial data are in the similar projected coodinates system.
tmap_mode("view")
tm_shape(town) +
tm_polygons() +
tm_shape(village) +
tm_polygons() +
tm_shape(stores) +
tm_dots()tmap_mode("plot")18.3.2 Importing aspatial data
Next, read_csv() of readr package will be used to import the two aspatial data sets into R environment.
pop2019 <- read_csv(
"chap18/data/aspatial/pop2019.csv")
store_sales <- read_csv(
"chap18/data/aspatial/Store_sales_data.csv")summary(store_sales) Store Code POD code Bills Amount
Length:5499 Length:5499 Min. : 1.0 Min. : 0
Class :character Class :character 1st Qu.: 37.0 1st Qu.: 26703
Mode :character Mode :character Median : 186.0 Median : 139643
Mean : 331.9 Mean : 236787
3rd Qu.: 457.0 3rd Qu.: 331952
Max. :7764.0 Max. :6076060
Ave Bill
Min. : 0.0
1st Qu.: 661.3
Median : 730.5
Mean : 825.1
3rd Qu.: 862.2
Max. :24356.0 18.4 Data Preparation
18.4.1 Aggregating store sales
Code chunk below is used to aggregate the store sales data at Store Code.
store_sales_aggre <- store_sales %>%
group_by(`Store Code`) %>%
summarise(
"Total_Bill" = sum(Bills, na.rm = TRUE),
"Total_Sales" = sum(Amount, na.rm = TRUE))18.4.2 Relational join
In the code chunk below, left_join() of dplyr package is used to append data from store_sales data.frame onto stores sf data.frame. At the same time a new field called Store_size has been created.
stores <- stores %>%
left_join(store_sales_aggre,
by = join_by(
Store_CD == `Store Code`)) %>%
mutate(Store_size = 100)Next, summary() is used to check if the are any missing values in the data.frame.
summary(stores) Store_Name Store_Addr Store_CD Total_Bill
Length:28 Length:28 Length:28 Min. : 1767
Class :character Class :character Class :character 1st Qu.: 5698
Mode :character Mode :character Mode :character Median : 8634
Mean : 8021
3rd Qu.:10349
Max. :14468
Total_Sales geometry Store_size
Min. :1475963 POINT :28 Min. :100
1st Qu.:4044821 epsg:3826 : 0 1st Qu.:100
Median :6116336 +proj=tmer...: 0 Median :100
Mean :5542852 Mean :100
3rd Qu.:6959911 3rd Qu.:100
Max. :8234234 Max. :100 18.4.3 Tidying pop2019 data.frame
We are planning to append data in pop2019 data.frame onto village sf data.frame. Before we can do so, it is wise to check in to values in the join field are the same.
glimpse(pop2019)Rows: 625
Columns: 11
$ COUNTY_ID <dbl> 66000, 66000, 66000, 66000, 66000, 66000, 66000, 66000, 6600…
$ COUNTY <chr> "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中市…
$ TOWN_ID <dbl> 66000110, 66000110, 66000110, 66000110, 66000110, 66000110, …
$ TOWN <chr> "大甲區", "大甲區", "大甲區", "大甲區", "大甲區", "大甲區", "大甲區", "大甲區", "大甲區…
$ V_ID <chr> "66000110-002", "66000110-009", "66000110-021", "66000110-00…
$ VILLAGE <chr> "大甲里", "中山里", "太白里", "孔門里", "文曲里", "文武里", "日南里", "平安里", "江南里…
$ H_CNT <dbl> 454, 1781, 406, 383, 355, 2071, 2039, 785, 461, 559, 769, 80…
$ P_CNT <dbl> 1255, 5252, 1471, 1001, 1264, 6687, 6739, 2642, 1618, 1977, …
$ M_CNT <dbl> 626, 2533, 758, 538, 640, 3244, 3406, 1310, 838, 983, 1273, …
$ F_CNT <dbl> 629, 2719, 713, 463, 624, 3443, 3333, 1332, 780, 994, 1239, …
$ INFO_TIME <chr> "108Y12M", "108Y12M", "108Y12M", "108Y12M", "108Y12M", "108Y…glimpse(village)Rows: 622
Columns: 11
$ VILLCODE <chr> "66000110029", "66000120001", "66000120002", "66000120003",…
$ COUNTYNAME <chr> "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中市", "臺中…
$ TOWNNAME <chr> "大甲區", "清水區", "清水區", "清水區", "清水區", "清水區", "清水區", "清水區", "清水…
$ VILLNAME <chr> "建興里", "鰲峰里", "靈泉里", "清水里", "文昌里", "南寧里", "西寧里", "北寧里", "中興…
$ VILLENG <chr> "Jianxing Vil.", "Aofeng Vil.", "Lingquan Vil.", "Qingshui …
$ COUNTYID <chr> "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B",…
$ COUNTYCODE <chr> "66000", "66000", "66000", "66000", "66000", "66000", "6600…
$ TOWNID <chr> "B11", "B12", "B12", "B12", "B12", "B12", "B12", "B12", "B1…
$ TOWNCODE <chr> "66000110", "66000120", "66000120", "66000120", "66000120",…
$ NOTE <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ geometry <MULTIPOLYGON [m]> MULTIPOLYGON (((211953.9 27..., MULTIPOLYGON (…The plot above shown that the village ID (i.e. V_ID) in pop2019 data.frame is not in the same structure as the village code in village sf data.frame.
Code chunk below will be used to remove the “-” sign from the values.
pop2019 <- pop2019 %>%
mutate(V_ID = str_remove_all(
V_ID, "-"))Now, we are ready to append data in pop2019 data.frame onto village sf data.frame by using left_join() of dplyr package.
village <- village %>%
left_join(pop2019,
by = join_by(
VILLCODE == V_ID))18.4.4 Check for missing or zero values
Code chunk below is used to check in any records with missing values.
summary(village) VILLCODE COUNTYNAME TOWNNAME VILLNAME
Length:622 Length:622 Length:622 Length:622
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
VILLENG COUNTYID COUNTYCODE TOWNID
Length:622 Length:622 Length:622 Length:622
Class :character Class :character Class :character Class :character
Mode :character Mode :character Mode :character Mode :character
TOWNCODE NOTE COUNTY_ID COUNTY
Length:622 Length:622 Min. :66000 Length:622
Class :character Class :character 1st Qu.:66000 Class :character
Mode :character Mode :character Median :66000 Mode :character
Mean :66000
3rd Qu.:66000
Max. :66000
NA's :5
TOWN_ID TOWN VILLAGE H_CNT
Min. :6.6e+07 Length:622 Length:622 Min. : 180
1st Qu.:6.6e+07 Class :character Class :character 1st Qu.: 724
Median :6.6e+07 Mode :character Mode :character Median :1335
Mean :6.6e+07 Mean :1592
3rd Qu.:6.6e+07 3rd Qu.:2195
Max. :6.6e+07 Max. :7599
NA's :5 NA's :5
P_CNT M_CNT F_CNT INFO_TIME
Min. : 487 Min. : 257 Min. : 230 Length:622
1st Qu.: 2139 1st Qu.:1095 1st Qu.:1053 Class :character
Median : 3862 Median :1911 Median :1934 Mode :character
Mean : 4545 Mean :2234 Mean :2311
3rd Qu.: 6151 3rd Qu.:3022 3rd Qu.:3171
Max. :18652 Max. :8741 Max. :9911
NA's :5 NA's :5 NA's :5
geometry
MULTIPOLYGON :622
epsg:3826 : 0
+proj=tmer...: 0
The output print above revealed that the are five missing values in H_CNT, P_CNT, M_CNT and F_CNT fields.
Hence, code chunk below is used to remove the five records with missing values from village sf data.frame.
village <- village %>%
filter(!is.na(P_CNT)) any(is.na(village$H_CNT))[1] FALSEany(is.na(village$P_CNT))[1] FALSEany(is.na(village$M_CNT))[1] FALSEany(is.na(village$F_CNT))[1] FALSE18.5 Computing Distance Matrix
Instead of calculate the distance between the villages and stores, we will calculate the centroid of each village using the code chunk below. Then, compute the distance between the centroids of the villages and the stores.
village_center <- st_point_on_surface(village)
distmat <- st_distance(village_center, stores) Next, the code chunk below is used to convert the distance matrix into long data.frame format
rownames(distmat) <- village$`VILLCODE`
colnames(distmat) <- stores$`Store_CD`
distmat_long <- distmat %>%
as.data.frame() %>%
rownames_to_column(var = "VILLCODE") %>%
pivot_longer(
cols = -VILLCODE,
names_to = "Store_CD",
values_to = "distance"
) %>%
mutate(distance = as.numeric(distance)) 18.6 Preparing Interaction Matrix
Code chunk below will be used to build the interaction matrix required by MCI package.
interaction_matrix <- distmat_long %>%
left_join(
stores %>%
st_drop_geometry() %>%
select(Store_CD, Store_size),
by = "Store_CD") %>%
relocate(
distance, .after = last_col())summary(interaction_matrix) VILLCODE Store_CD Store_size distance
Length:17276 Length:17276 Min. :100 Min. : 108.5
Class :character Class :character 1st Qu.:100 1st Qu.: 6678.7
Mode :character Mode :character Median :100 Median :11965.3
Mean :100 Mean :12762.7
3rd Qu.:100 3rd Qu.:18122.3
Max. :100 Max. :41395.4 18.7 Computing Huff model
huff_share <- huff.shares(
interaction_matrix, "VILLCODE", "Store_CD",
"Store_size", "distance")18.7.1 Trade area analysis for a single store
First, let us select market share data of a store by using Store_CD field (i.e. TG).
market_share <- huff_share %>%
filter(Store_CD == "BT")Next, trade areas of the selected will be derived by using the code chun below.
Trade_area <- village %>%
left_join(market_share)Before plotting the trade area map, code chunk below is used to extract the selected store from stores sf data.frame.
selected_store <- stores %>%
filter(Store_CD == "BT")Now, use the code chunk below to plot the trade areas of the selected store.
tm_shape(Trade_area) +
tm_polygons(fill = "p_ij",
fill.scale = tm_scale_intervals(
style = "quantile",
n = 10,
values = "brewer.blues"),
fill.legend = tm_legend(
title = "Patronage Probability")) +
tm_shape(selected_store) +
tm_dots(size = 0.3,
fill = "red",
col = "black") +
tm_title("Distribution of Patronage Probability of Store BT by village") +
tm_layout(frame = TRUE) +
tm_borders(fill_alpha = 0.5) +
tm_compass(type="8star", size = 2) +
tm_scalebar() +
tm_grid(alpha =0.2) 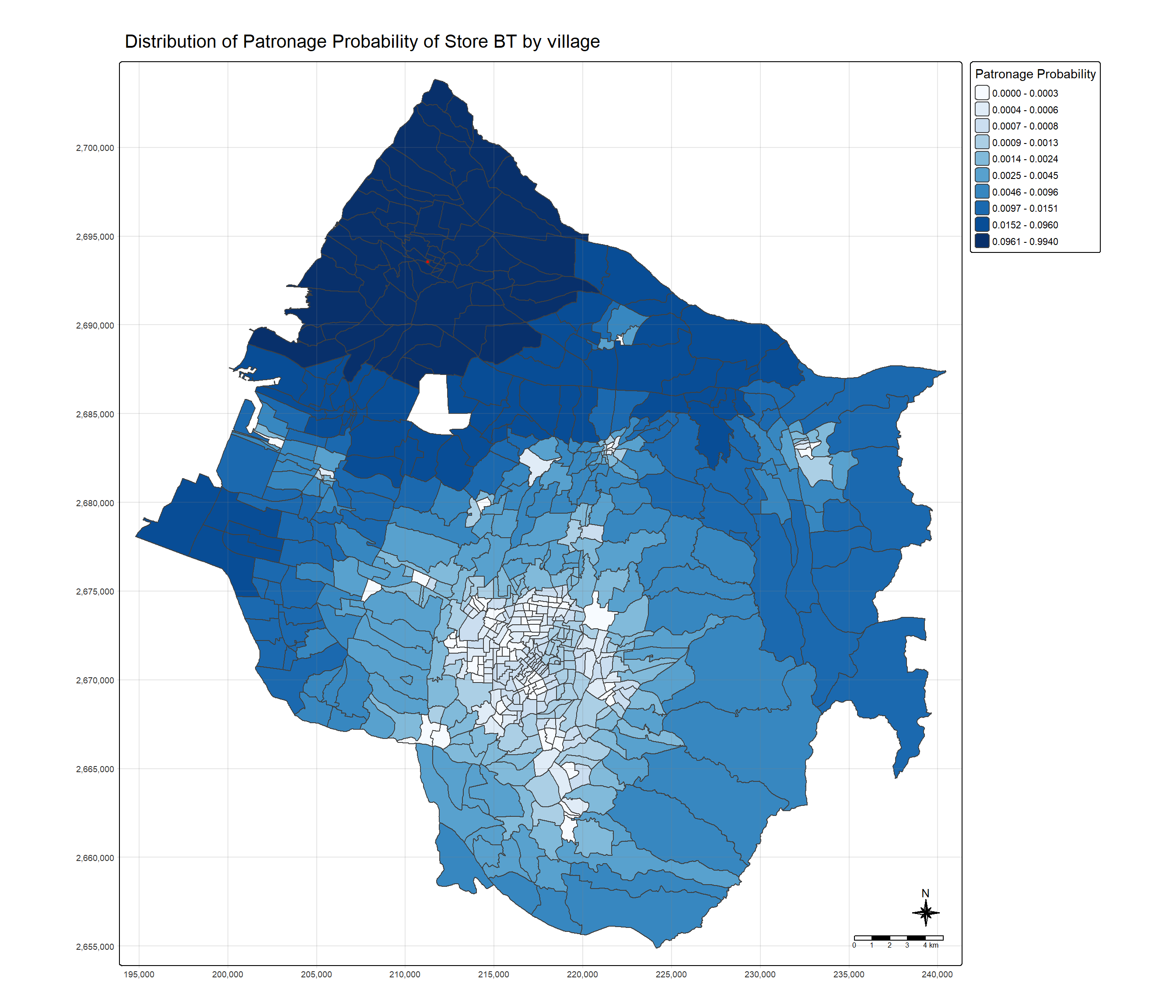
18.7.2 Store sales analysis
One of the usage of Huff model is to estimate the store sales by using village population.
Firstly, let us append P_CNT field from village sf.data.frame to huff_share data.frame by using the code chunk below.
huff_share_pp <- huff_share %>%
left_join(village %>%
st_drop_geometry() %>%
select(VILLCODE, P_CNT),
by = "VILLCODE") %>%
relocate(
distance, .after = last_col())Next, shares.total() of MCI package will be used to calculate the total sales by using the code chunk below.
huff_total <- shares.total(
huff_share_pp, "VILLCODE", "Store_CD",
"p_ij", "P_CNT")Code chunk below is used to append the estimate store sales (Ej) onto stores sf data.frame.
store_sales_est <- stores %>%
left_join(huff_total,
by = join_by(
"Store_CD" == "suppliers_single"))Now, we can visualise how well the estimate sales as compare to the actual sales by using the code chunk below.
store_sales_nongeom <- store_sales_est %>%
st_drop_geometry()
ggscatterstats(
store_sales_nongeom,
x = sum_E_j,
y = Total_Sales)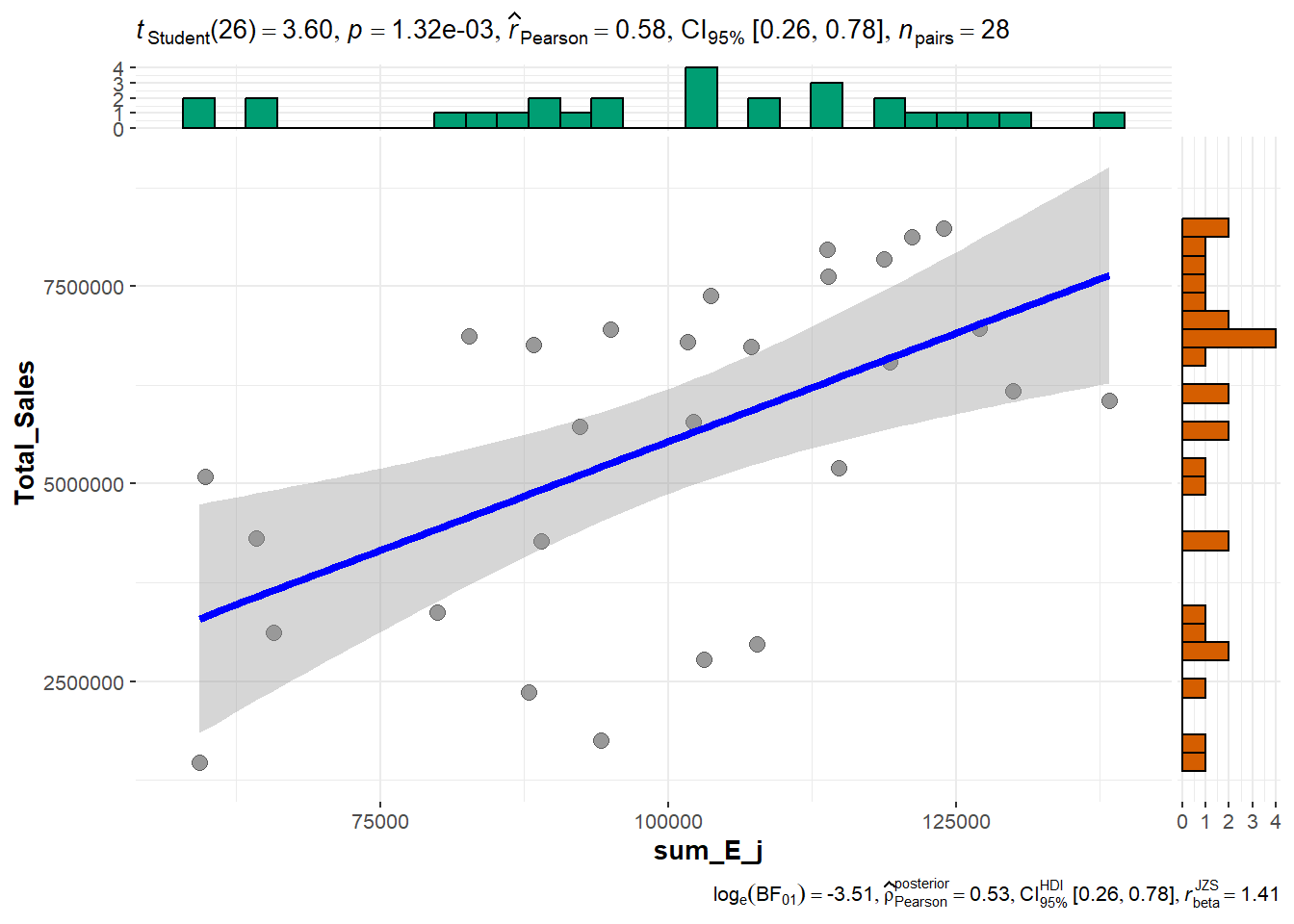
huff_share_wider <- huff_share %>%
select(VILLCODE, Store_CD, p_ij) %>%
pivot_wider(names_from = Store_CD,
values_from = p_ij)